What is generative AI and ChatGPT?
ChatGPT is a kind of technology known as “generative AI.” Generative AI is a fairly cutting-edge technology that allows users to generate new content – words, images, and now even videos – by entering a prompt into a system that guides it to create a specified output.
ChatGPT, arguably the most well-known generative AI product, was developed by Californian tech company OpenAI. Since OpenAI released ChatGPT in November 2022, the generative AI race is on. Multiple tech companies, including Google, Amazon, and Baidu, have since released their own generative AI products. Microsoft has invested billions in OpenAI and uses ChatGPT in a generative version of its search engine, Bing. Elon Musk is also reportedly gearing up to launch a new generative AI-focused company.
It’s important to note that generally only big or exceptionally well-funded companies can build these products because of the significant financial and technical resources required to make and run them, including access to massive amounts of data and computing power. If generative AI is the future, then this is a vision proposed and realized by a handful of powerful tech companies and individuals, each with their own commercial interests at stake. This raises important questions about corporate power and accountability.
What feeds generative AI?
Generative AI models are trained on vast amounts of data. It’s problematic when training data and training processes aren’t publicly available, as is the case for GPT4, the newest image and text generative AI product from OpenAI. We do know that GPT3, OpenAI’s previous model, was trained on text scraped from a large number of internet sources, including Reddit boards.
Using billions of images and text from across the internet as training data, without careful filtering and moderation, risks perpetuating the worst content-related problems we already see online – presenting opinions as facts, creating believable false images or videos, reinforcing structural biases, and generating harmful, discriminatory content, to name a few.

Research shows that content on the web is simply not representative of most people’s lived realities. For example, Wikipedia still has a huge bias towards showing information about men and about the so-called Global North, despite significant efforts to address content inequities. Generative AI systems trained on unrepresentative data simply reproduce inequities from existing internet content.
Companies scraping people’s content without their knowledge or consent for training data has obvious privacy implications too. How do you know when your image or text has been used to train a generative AI system? How do you ask for it to be removed from the system?
How is this technology different from what’s already available online?
This is really the first time that advanced, creative AI applications are accessible to anyone with a computer or smartphone. But there is a still a massive English-language dominance in both text and image generative AI applications, so it’s very limited in accessibility in that sense.
Human Rights Watch has been working on the human rights impact of AI issues for the past five years, and generative AI is in many ways an extension of well-known concerns about AI and machine learning technology – that there is a heightened risk of surveillance, discrimination, and a lack of accountability for when things go wrong.
What are some of the concerns around privacy and data security?
Be careful what you type into generative AI tools! We should assume that everything we input into generative AI products is to some extent being used to train and “improve” the model. It may also be visible to the tech company that owns or uses the system. Companies across multiple sectors are now asking their staff to refrain from entering sensitive or personal information into generative AI systems.
Even when we enter seemingly mundane information into generative AI search or chatbots, this could be used to build a picture of who we are. AI is particularly good at noticing patterns, and what we search for or type in chatbots could over time disclose sensitive insights about our identity or behavior from content that we don't naturally think of as especially revealing information.
Right now, we just don’t have enough information to know to what extent our information is being used and can be linked to individual identities. We need answers from tech companies on how they will respect privacy rights with regards to generative AI. It’s worth noting that OpenAI increased ChatGPT privacy controls last week following a “ban” on the product in Italy over data protection concerns. This is very much a developing landscape.
Are these reliable systems?
We simply cannot give too much weight to systems that are known to contain falsehoods and inaccuracies, especially when they are opaque in design. For example, Google’s chatbot, Bard, gave an answer containing a factual error at its launch. You could just use Google search to find the right answer, although you may need to sift through wrong answers before finding the right one. But with some generative AI systems you can’t easily see the information's sources, something that helps people critically evaluate whether to trust the output.
It’s worth noting that there are additional safety concerns around generative AI chatbots that can make them seem authoritative and somewhat human-sounding because of their design and conversational tone. This can lead users to place far too much trust in them.
The consequences for this are serious. There’s the case of the judge in Colombia who said he queried ChatGPT while preparing a judgement. How much could this tech influence a courtroom decision? In Belgium, a woman says her husband died by suicide after his interactions with a generative AI chatbot.
We need tech makers and regulators to pause and consider some of the big questions: How could this be misused? Even with the best of intentions, what could go wrong? Can this cause harm and if so, what can we do about it?
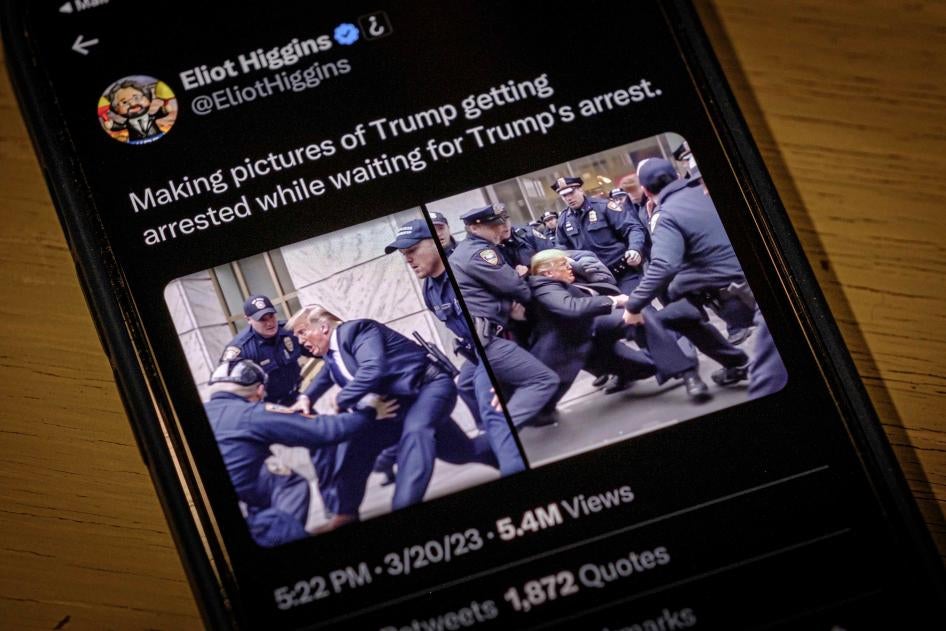
Companies are rushing to put out products that are simply not safe for general use. Earlier versions of generative AI chatbots led to outputs that were problematic and biased. We know that the current industry competition stokes a race to the bottom, rather than one based on policy and practice that is aligned with human rights.
Tech companies have human rights responsibilities that are especially important when they’re creating new powerful and exploratory technology. They need to show clearly that they are identifying and mitigating human rights risks in advance of the release of any product. They also need to be held to account for any harm resulting from their products. To do that, training data, design values, and content moderation processes must be open to independent scrutiny.
It seems misinformation could run rampant with this technology. Are you concerned about that?
Yes, that’s likely going to be a big problem. Generative AI could vastly change how we use the internet by changing how we find and trust information online. How do you trust what you see? With developments like text-to-image models and text-to-video, we are opening pandora’s box on the trustworthiness of internet content. We already have a problem knowing what is real, and that is about to get a whole lot bigger. This can have devastating consequences, say, in political events like elections or in conflict and crisis situations.
There are some generative AI chatbots that impersonate historical figures and government officials. People could publish text that, if taken seriously, might be used to whitewash serious crimes and human rights violations.
What about the people sifting through data to feed these chatbots?
Building AI involves a lot of invisible human labor. Someone needs to label the training data, and someone also needs to decide whether the machine is getting things right or wrong. This process relies on humans inputting information, which means the technology inevitably includes human biases.
Exploitation of workers in the creation of AI is another key human rights issue. An investigation by Time magazine showed how OpenAI outsourced its data labeling for ChatGPT to Sama, a company that employed workers in Kenya to work in grueling conditions, some paid less than $2 an hour for sifting through toxic and biased data.
Tech companies outsource this labor to workforces largely in the Global South. There’s a huge divide between working conditions in US tech companies’ headquarters and in the places fueling these technologies. The workers that build AI often witness the worst parts of the internet, and they deserve better. All companies have a responsibility to provide a living wage and dignity at work.
What types of regulations exist to control this technology?
Tech companies have tried to stay ahead of regulation by attempting to self-regulate, for instance by writing and adopting principles or guidelines they would nominally hold themselves to. Under its AI principles, for instance, Google has said it would not release AI products whose purpose contravenes human rights. But expecting tech companies to follow their own principles puts too much trust in self-governance. AI is simply too powerful, and the consequences for rights are too severe, for companies to regulate themselves.
All companies have a responsibility to respect human rights standards and take measures to identify, prevent, and mitigate human rights risks that they cause, contribute to, or are linked with through their own operations or operations in their value chains. These responsibilities are laid out in the United Nations Guiding Principles on Business and Human Rights as well as guidelines from the Organisation for Economic Cooperation and Development. We need to translate the UN guiding principles into binding law, not just for AI, but for all technology.
Lawmakers have been struggling to keep pace with new tech industry developments over the past few years, but we are now seeing the emergence of AI regulation at national and regional levels. A big one is the European Union’s AI Act, which passed an initial vote last week with the proposal to address copyright issues in generative AI. Let’s see whether that goes far enough to address the human rights concerns this tech raises, though.
How does this technology impact human rights investigations?
There is an important role for human rights organizations to expose and challenge how emerging technologies are being developed, and this includes products that use generative AI.
But there’s also a real threat to human rights investigations with generative AI. Advances in this technology mean it’s now possible to create believable content quickly and easily, which is undoubtedly going to create new challenges for human rights groups that collect evidence to document abuses and hold injustices to account. The work of Human Rights Watch’s Digital Investigations Lab and their ability to fact-check and verify content is going to be increasingly important in a future of generative AI, as fake or misleading information, including very believable photos and videos generated by AI, circulate online.
*This interview has been edited and condensed.




