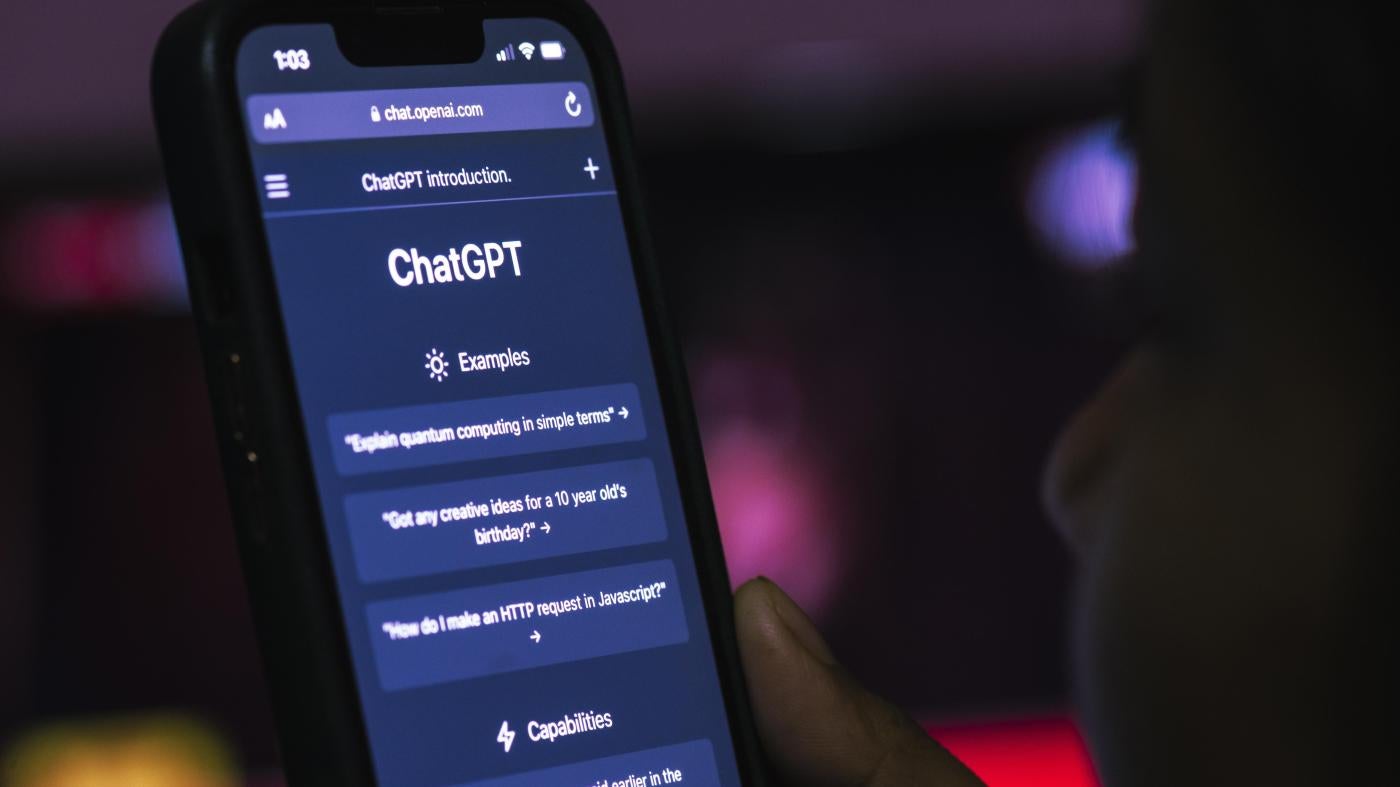
Was ist generative KI und ChatGPT?
ChatGPT ist eine Technologie, die als „generative KI“ bezeichnet wird. Generative KI ist eine sehr innovative Technologie, die es Nutzer*innen ermöglicht, neue Inhalte - Wörter, Bilder und jetzt auch Videos - zu generieren, indem sie einen Befehl in ein System eingeben, den das System dann nutzt, um einen bestimmten Output zu kreieren.
ChatGPT, das wohl bekannteste generative KI-Produkt, wurde vom kalifornischen Technologieunternehmen OpenAI entwickelt. Seit OpenAI ChatGPT im November 2022 veröffentlicht hat, ist das Rennen um die generative KI in vollem Gange. Mehrere andere Tech-Unternehmen, darunter Google, Amazon und Baidu, haben seitdem ihre eigenen generativen KI-Produkte veröffentlicht. Microsoft hat Milliarden in OpenAI investiert und verwendet ChatGPT in einer generativen Version seiner Suchmaschine Bing. Berichten zufolge bereitet auch Elon Musk die Gründung eines neuen, auf generative KI fokussierten, Unternehmens vor.
Es ist wichtig anzumerken, dass in der Regel nur große oder besonders finanzstarke Unternehmen diese Produkte entwickeln können, da für ihre Entwicklung und ihren Einsatz erhebliche finanzielle und technische Ressourcen erforderlich sind, darunter der Zugang zu großen Datenmengen und Rechnerleistung. Wenn generative KI die Zukunft ist, dann ist dies eine Vision, die von einer Handvoll mächtiger Technologieunternehmen und Einzelpersonen erdacht und verwirklicht wird, die jeweils ihre eigenen kommerziellen Interessen im Blick haben. Das wirft wichtige Fragen zur Macht und Rechenschaftspflicht von Unternehmen auf.
Woraus speist sich generative KI?
Generative KI-Tools werden mittels riesiger Datenmengen quasi trainiert. Problematisch wird es, wenn die Trainingsdaten und -prozesse nicht öffentlich zugänglich sind, wie es bei GPT4 der Fall ist, dem neuesten generativen KI-Produkt für Bilder und Texte von OpenAI. Wir wissen, dass GPT3, das Vorgängermodell von OpenAI, auf Text trainiert wurde, der aus einer großen Anzahl von Internetquellen, u.a. Reddit-Foren, zusammengetragen wurde.
Die Verwendung von Milliarden von Bildern und Texten aus dem gesamten Internet als Trainingsdaten ohne sorgfältige Sichtung und Prüfung birgt die Gefahr, dass die schlimmsten inhaltlichen Probleme, die wir bereits im Internet beobachten, verstärkt werden - die Darstellung von Meinungen als Fakten, die Erstellung echt wirkender Bilder oder Videos, die Verstärkung struktureller Vorurteile und die Erzeugung schädlicher, diskriminierender Inhalte, um nur einige zu nennen.

Untersuchungen zeigen, dass die Inhalte im Internet einfach nicht repräsentativ für die Lebenswirklichkeit der meisten Menschen sind. So zeigt Wikipedia trotz erheblicher Bemühungen, inhaltliche Ungleichheiten zu beseitigen, immer noch eine starke Tendenz zur Darstellung von Informationen über Männer und den globalen Norden. Generative KI-Systeme, die mittels nicht repräsentativer Daten trainiert werden, reproduzieren einfach die bereits bestehenden Ungleichheiten der Internetinhalte.
Wenn Unternehmen die Inhalte von Menschen ohne deren Wissen oder Zustimmung für Trainingsdaten auslesen, hat das natürlich auch Auswirkungen auf den Datenschutz. Woher sollen Sie wissen, dass Ihr Bild oder Text für das Training eines generativen KI-Systems verwendet wurde? Wie können Sie verlangen, dass sie aus dem System entfernt werden?
Wie unterscheidet sich diese Technologie von dem, was bereits online verfügbar ist?
Dies ist tatsächlich das erste Mal, dass innovative, kreative KI-Anwendungen für jeden zugänglich sind, der einen Computer oder ein Smartphone besitzt. Aber sowohl bei den text- als auch bei den bildgenerativen KI-Anwendungen dominiert immer noch die englische Sprache, so dass die Zugänglichkeit in dieser Hinsicht stark eingeschränkt ist.
Human Rights Watch befasst sich seit fünf Jahren mit den Auswirkungen von KI auf die Menschenrechte. Generative KI erweitert in vielerlei Hinsicht die bekannten Bedenken gegenüber KI und maschinellen Lerntechnologien - dass es ein erhöhtes Risiko von Überwachung, Diskriminierung und mangelnder Rechenschaftspflicht gibt, wenn etwas schiefläuft.
Welche Bedenken gibt es in Bezug auf den Datenschutz und die Datensicherheit?
Man sollte auf jeden Fall vorsichtig sein bei allem, was man in generative KI-Tools eingibt! Wir sollten davon ausgehen, dass alles, was wir dort eingeben, bis zu einem gewissen Grad zum Training und zur „Verbesserung“ des Modells verwendet wird. Es kann auch für das Technologieunternehmen, welches das jeweilige System besitzt oder nutzt, sichtbar sein. Unternehmen aus verschiedenen Branchen fordern ihre Mitarbeitenden auf, keine sensiblen oder persönlichen Daten in generative KI-Systeme einzugeben.
Selbst wenn wir scheinbar alltägliche Informationen in generative KI-Such- oder Chatbots eingeben, können diese genutzt werden, um ein Profil von uns zu erstellen. KI ist besonders gut darin, Muster zu erkennen. Was wir suchen oder in Chatbots eingeben, könnte im Laufe der Zeit sensible Erkenntnisse über unsere Identität oder unser Verhalten offenlegen, und zwar anhand von Inhalten, die wir für sich genommen nicht als besonders aufschlussreiche Informationen erachten.
Im Moment haben wir schlicht nicht genug Informationen, um abschätzen zu können, in welchem Ausmaß unsere Daten verwendet werden und etwa Einzelpersonen zugeordnet werden können. Wir brauchen Antworten von Technologieunternehmen darauf, wie sie die Datenschutzrechte in Bezug auf generative KI respektieren wollen. Es ist erwähnenswert, dass OpenAI letzte Woche die Datenschutzkontrollen für ChatGPT verstärkt hat, nachdem das Produkt in Italien wegen Datenschutzbedenken verboten worden war. Das ist alles quasi noch Entwicklungsneuland.
Sind diese Systeme zuverlässig?
Wir dürfen Systeme, von denen bekannt ist, dass sie Unwahrheiten und Ungenauigkeiten enthalten, einfach nicht zu mächtig werden lassen, insbesondere wenn sie intransparent konzipiert werden. Der Chatbot von Google, Bard, hat zum Beispiel zu Beginn eine Antwort gegeben, die einen sachlichen Fehler enthielt. Man könnte einfach die Google-Suche verwenden, um die richtige Antwort zu finden, auch wenn man sich durch falsche Antworten durcharbeiten muss, bevor man die richtige findet. Aber bei einigen generativen KI-Systemen kann man die Quellen der Informationen nicht ohne Weiteres sehen, was den Menschen jedoch helfen würde, kritisch zu beurteilen, ob sie dem Ergebnis vertrauen können.
Außerdem gibt es Sicherheitsbedenken in Bezug auf generative KI-Chatbots gibt, die aufgrund ihres Designs und ihres sprachlichen Duktus autoritär und bisweilen menschlich wirken können. Dies kann dazu führen, dass die Nutzer*innen ihnen zu viel Vertrauen entgegenbringen.
Die Folgen sind gravierend. Da ist etwa der Fall des Richters in Kolumbien, der sagte, er habe ChatGPT bei der Vorbereitung eines Urteils genutzt. Wie sehr könnte diese Technologie die Entscheidung eines Gerichts beeinflussen? In Belgien sagt eine Frau, dass ihr Mann sich nach seinen Interaktionen mit einem generativen KI-Chatbot das Leben genommen hat.
Wir brauchen Entwickler*innen und Regulierungsbehörden, die sich bereits vorab einige der wichtigsten Fragen stellen: Wie könnte diese Technik missbraucht werden? Was könnte selbst bei besten Absichten schiefgehen? Kann dies Schaden anrichten und wenn ja, was können wir dagegen tun?
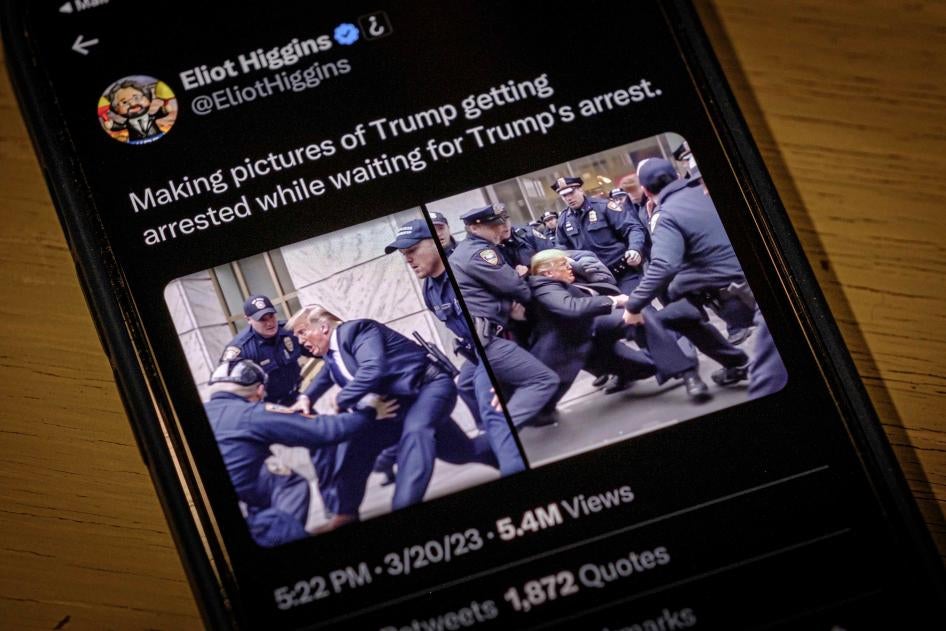
Unternehmen bringen in aller Eile Produkte auf den Markt, die für den allgemeinen Gebrauch einfach nicht sicher sind. Frühere Versionen von generativen KI-Chatbots haben zu problematischen und voreingenommenen Ergebnissen geführt. Wir wissen, dass der derzeitige Wettbewerb in der Branche das Wettrennen unter den Unternehmen anheizt. Das führt dazu, dass Menschenrechtsfragen oft außer Acht gelassen werden.
Technologieunternehmen haben jedoch eine menschenrechtliche Verantwortung, die besonders wichtig ist, wenn sie neue leistungsstarke Technologien entwickeln. Sie müssen klar nachweisen können, dass sie Menschenrechtsrisiken bereits vor der Markteinführung eines Produkts erkennen und abmildern. Außerdem müssen sie für alle Schäden, die durch ihre Produkte entstehen, zur Verantwortung gezogen werden. Um dies zu erreichen, müssen die Trainingsdaten, die Designwerte und die Moderationsprozesse für eine unabhängige Prüfung zur Verfügung stehen.
Es scheint, dass mit dieser Technologie Falschinformationen überhandnehmen könnten. Bereitet dir das Sorge?
Ja, das wird wahrscheinlich ein großes Problem. Generative KI könnte unser Online-Verhalten grundlegend verändern, indem sie die Art und Weise, wie wir Informationen online finden und ihnen vertrauen, verändert. Woher weiß man, dass das, was man sieht, authentisch ist? Mit Entwicklungen wie Text-zu-Bild und Text-zu-Video-Modellen öffnen wir die Büchse der Pandora, was die Vertrauenswürdigkeit von Internetinhalten angeht. Wir haben schon jetzt Probleme damit, zu erkennen, was echt ist, und das ist erst der Anfang. Das kann verheerende Folgen haben, etwa bei politischen Ereignissen wie Wahlen oder in Konflikt- und Krisensituationen.
Es gibt generative KI-Chatbots, die sich als historische Persönlichkeiten und Regierungsmitglieder ausgeben. Menschen könnten Texte veröffentlichen, die, wenn sie ernst genommen werden, dazu verwendet werden könnten, schwere Verbrechen und Menschenrechtsverletzungen zu beschönigen.
Was ist mit den Menschen, die die Daten durchforsten, um diese Chatbots zu füttern?
Die Entwicklung von KI erfordert eine Menge unsichtbarer menschlicher Arbeit. Jemand muss die Trainingsdaten kennzeichnen, und jemand muss auch entscheiden, ob die Maschine etwas richtig oder falsch macht. Dieser Prozess beruht auf der Eingabe von Informationen durch Menschen, was bedeutet, dass die Technologie unweigerlich die Voreingenommenheit von Menschen übernimmt.
Die Ausbeutung von Arbeitnehmer*innen bei der Entwicklung von KI ist ein weiteres zentrales Menschenrechtsproblem. Eine Untersuchung des Time-Magazins zeigte, wie OpenAI die Datenkennzeichnung für ChatGPT an Sama auslagerte, ein Unternehmen, das Arbeiter*innen in Kenia unter zermürbenden Bedingungen beschäftigte. Einige von ihnen sichteten für weniger als 2 Dollar pro Stunde schädliche und voreingenommene Inhalte.
Technologieunternehmen lagern diese Arbeit an Arbeitskräfte vor allem im globalen Süden aus. Es besteht eine große Kluft zwischen den Arbeitsbedingungen in den Zentralen der US-Tech-Unternehmen und den Orten, an denen diese Technologien entwickelt werden. Die Menschen, die KI entwickeln, erleben oft die schlimmsten Seiten des Internets, und sie verdienen Besseres. Alle Unternehmen sind dafür verantwortlich, für einen existenzsichernden Lohn und menschenwürdige Arbeitsbedingungen zu sorgen.
Welche Vorschriften gibt es, um diese Technologien zu kontrollieren?
Technologieunternehmen haben versucht, der staatlichen Regulierung einen Schritt voraus zu sein. Sie versuchten, sich selbst zu regulieren, indem sie zum Beispiel Grundsätze oder Leitlinien aufstellten und verabschiedeten, an die sie sich i.d.R. nominell halten. Im Rahmen seiner KI-Grundsätze hat Google beispielsweise erklärt, dass es keine KI-Produkte herausgeben wird, deren Zweck gegen die Menschenrechte verstößt. Aber wenn man von Technologieunternehmen erwartet, dass sie ihre eigenen Grundsätze befolgen, setzt man zu viel Vertrauen in deren Eigenverantwortung. KI ist einfach zu mächtig, und die Folgen für die Menschenrechte sind zu schwerwiegend, als dass die Unternehmen sich selbst regulieren könnten und sollten.
Alle Unternehmen sind dafür verantwortlich, die Menschenrechtsstandards zu respektieren und Maßnahmen zu ergreifen, um Menschenrechtsrisiken zu erkennen, zu verhindern und abzumildern, die sie durch ihre eigene Tätigkeit oder durch Tätigkeiten entlang ihrer Wertschöpfungsketten verursachen, zu denen sie beitragen oder mit denen sie in Verbindung stehen. Diese Verantwortung ist in den Leitprinzipien der Vereinten Nationen für Wirtschaft und Menschenrechte sowie in den Leitlinien der Organisation für wirtschaftliche Zusammenarbeit und Entwicklung verankert. Wir müssen die UN-Leitprinzipien in verbindliches Recht umsetzen, nicht nur für KI, sondern für alle Technologien.
Die Gesetzgeber haben in den letzten Jahren Mühe gehabt, mit den neuen Entwicklungen in der Technologiebranche Schritt zu halten. Nach und nach werden nun auf nationaler und regionaler Ebene KI-Vorschriften eingeführt. Ein wichtiges Beispiel ist das KI-Gesetz der Europäischen Union, über das letzte Woche eine erste Abstimmung stattfand und das Urheberrechtsfragen im Bereich der generativen KI regeln soll. Es bleibt abzuwarten, ob das Gesetz weit genug geht, um die Menschenrechtsprobleme, die diese Technologie aufwirft, zu lösen.
Wie wirkt sich diese Technologie auf die Menschenrechtsarbeit aus?
Menschenrechtsorganisationen spielen eine wichtige Rolle, wenn es darum geht, die Entwicklung neuer Technologien aufzudecken und in Frage zu stellen. Dazu gehören auch Produkte, die generative KI nutzen.
Aber generative KI birgt auch eine echte Bedrohung für die Menschenrechtsarbeit. Fortschritte in dieser Technologie bedeuten, dass es jetzt möglich ist, schnell und einfach echt wirkende Inhalte zu erstellen. Dies wird zweifellos neue Herausforderungen für Menschenrechtsgruppen schaffen, die Beweise sammeln, um Missstände zu dokumentieren und Verantwortliche für Ungerechtigkeiten zur Rechenschaft zu ziehen. Die Arbeit des Digital Investigations Lab von Human Rights Watch und seine Fähigkeit, Inhalte zu prüfen und zu verifizieren, wird in einer Zukunft der generativen KI immer wichtiger werden, da immer mehr gefälschte oder irreführende Informationen online kursieren werden, wie etwa echt wirkende Fotos und Videos, die von KI generiert wurden.